IJCAI 2025,第34届国际人工智能联合会议(CCF A类国际顶级会议)
近日,南京大学智能感知与通信实验室刘一茳博士投稿的“FeedBack Quantization for Large Language Models”论文被人工智能领域顶级会议IJCAI 2025录用(CCF A类),论文指导老师为南京大学电子学院杜力教授,该论文作者均来自南京大学智能感知与通信实验室。以下为论文相关信息,更多细节请关注原文(点击跳转)
FBQuant: FeedBack Quantization for Large Language Models
Yijiang Liu1 , Hengyu Fang1 , Liulu He1 , Rongyu Zhang1 , Yichuan Bai1 , Yuan Du1,2 and Li Du1,2,✉
Abstract
Deploying Large Language Models (LLMs) on edge devices is increasingly important, as it eliminates reliance on network connections, reduces expensive API calls, and enhances user privacy. However, on-device deployment is challenging due to the limited computational resources of edge devices. In particular, the key bottleneck stems from memory bandwidth constraints related to weight loading. Weight-only quantization effectively reduces memory access, yet often induces significant accuracy degradation. Recent efforts to incorporate sub-branches have shown promise for mitigating quantization errors, but these methods either lack robust optimization strategies or rely on suboptimal objectives. To address these gaps, we propose FeedBack Quantization (FBQuant), a novel approach inspired by negative feedback mechanisms in automatic control. FBQuant inherently ensures that the reconstructed weights remain bounded by the quantization process, thereby reducing the risk of overfitting. To further offset the additional latency introduced by sub-branches, we develop an efficient CUDA kernel that decreases 60% of extra inference time. Comprehensive experiments demonstrate the efficiency and effectiveness of FBQuant across various LLMs. Notably, for 3-bit Llama2-7B, FBQuant improves zero-shot accuracy by 1.2%.
论文总结
针对大语言模型在端侧部署时面临的量化精度损失和过拟合挑战,我们创新性地提出了基于负反馈机制的Feed-Back Quantization (FBQuant) 方法。FBQuant首次揭示了子分支重建中的过拟合风险,并通过负反馈机制确保了优化收敛边界,增强了大模型量化过程的鲁棒性。为进一步提升子分支的推理效率,我们为其定制了高效的CUDA计算核,成功降低60%推理延时。实验表明FBQuant在3/4比特量化下性能均能达到最佳表现。
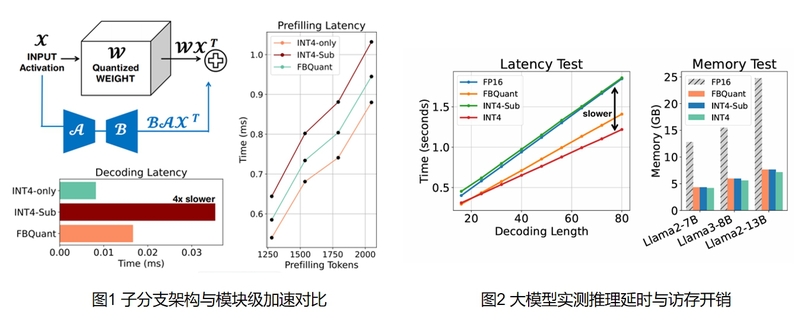
核心贡献
通过严谨的数学推导证明了FBQuant通过负反馈机制能确保稳定的收敛边界,有效应对传统方法下的过拟合风险。
为子分支定制了高效的CUDA 计算核,极大降低了其访存和计算开销。
在通用GPU平台上与半精度模型相比,降低30%延迟和75%显存。
实验结果
在Llama和Qwen等多个主流大模型家族的3/4比特量化下,FBQuant在多项benchmark测试下均达到最优表现。
Table 1. 七项任务基准中3比特量化模型的平均准确率对比表
Method | W-Bit | Llama2-7B | Llama2-13B | Llama2-70B | Llama3-8B | Llama3-70B | Qwen2.5-7B |
FP16 | 16 | 66.62 | 70.45 | 76.27 | 72.79 | 80.22 | 74.25 |
RTN | 3 | 62.17 | 68.33 | 73.97 | 61.51 | 68.61 | 67.21 |
GPTQ [1] | 3 | 59.68 | 67.16 | 73.39 | 63.63 | 77.19 | 70.73 |
AWQ [2] | 3 | 63.31 | 68.74 | 74.82 | 67.83 | 77.69 | 70.84 |
OmniQuant [3] | 3 | 63.48 | 67.96 | 74.55 | 67.97 | 77.81 | 70.98 |
CALDERA [4] | 3 | 62.1 | 66.13 | 73.56 | 63.48 | 77.17 | 64.45 |
SVDQuant [5] | 3 | 57.06 | 64.49 | 74.61 | 60.38 | 78.47 | 70.79 |
FBQuant | 3 | 64.68 | 69.11 | 75.77 | 68.87 | 78.99 | 72.16 |
参考文献
[1]Frantar, E., Ashkboos, S., Hoefler, T., & Alistarh, D. (2022). GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers. arXiv preprint arXiv:2210.17323.
[2] Lin, J., Tang, R., Tang, H., Yang, J., Liu, S., & Lin, J. (2023). AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration. arXiv preprint arXiv:2306.00978.
[3] Shao, W., Zhao, Z., Zhang, Q., Wang, P., Chen, K., & Yang, Y. (2023). OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models. arXiv preprint arXiv:2308.13137.
[4] Liu, S.-Y., Khadkevich, M., Fung, N. C., Sakr, C., Yang, C.-H. H., Wang, C.-Y., Muralidharan, S., Yin, H., Cheng, K.-T., Kautz, J., Wang, Y.-C. F., Molchanov, P., & Chen, M.-H. (2024). EoRA: Training-free Compensation for Compressed LLM with Eigenspace Low-Rank Approximation. arXiv preprint arXiv:2410.21271.
[5] Li, Y., Zhao, H., Yuan, Z., Li, X., & Gong, Y. (2023). SVDQuant: On the SVD-based Quantization for Large Language Models. arXiv preprint arXiv:2311.05929.